I find it easiest to understand the properties of different metrics by seeing how they sort simple timecourses. This example is adapted from Chapter 8 (Figure 8.1 and Table 8.1) of H. Charles Romesburg's Cluster Analysis for Researchers. This is a highly readable book, and I highly recommend it as a reference for distance metrics (he covers many more than I do here), clustering, tree methods, etc. The computer program sections are dated, but such a minor part of the text that it's not a problem.
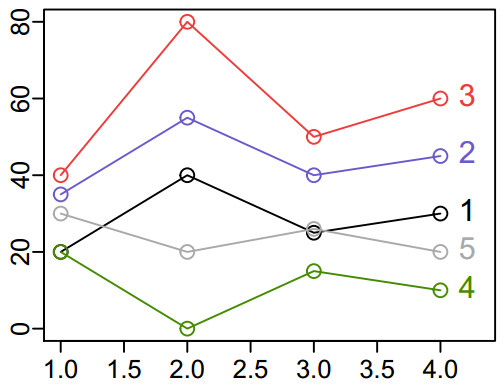
Here are the values for the same five lines:
data1 <- c(20,40,25,30);
data2 <- c(35,55,40,45);
data3 <- c(40,80,50,60);
data4 <- c(20, 0,15,10); # first four from Romesburg Table 8.1
data5 <- c(30,20,26,20); # and another line
Which lines are most similar? Three metrics.
 If we measure with Euclidean distance, lines 1 and 5 are closest. The little tree at right is built from the distance matrix printed below, using the R code that follows. I used R's built-in function to calculate the Euclidean distance between each pair of lines, putting the results into tbl in the format needed by hclust.
If we measure with Euclidean distance, lines 1 and 5 are closest. The little tree at right is built from the distance matrix printed below, using the R code that follows. I used R's built-in function to calculate the Euclidean distance between each pair of lines, putting the results into tbl in the format needed by hclust.Euclidean distance pretty much sorts the timecourses by their mean y: 1 is most similar (smallest distance) to 5, next-closest to 2, then 4, then 3 (read these distances from the first column in the table at right).
Thinking of these as fMRI timecourses, Euclidean distance pretty much ignores the "shape" of the lines (voxels): 1 and 5 are closest, even though voxel 1 has "more BOLD" at timepoint 2 and voxel 5 has "less BOLD" at timepoint 2. Likewise, voxel 1 is closer to voxel 4 (its mirror image) than to voxel 3, though I think most people would consider timecourses 1 and 3 more "similar" than 1 and 4.
tbl <- array(NA, c(5,5));
tbl[1,1] <- dist(rbind(data1, data1), method='euclidean');
tbl[2,1] <- dist(rbind(data1, data2), method='euclidean');
.... the other table cells ....
tbl[5,5] <- dist(rbind(data5, data5), method='euclidean');
plot(hclust(as.dist(tbl)), xlab="", ylab="", sub="", main="euclidean distance"); # simple tree
Pearson correlation sorts the timecourses very differently than Euclidean distance.

So, Pearson correlation may be suitable if you're more interested in shape than magnitude. In the fMRI context, we could say that correlation considers timecourses that go up and down together as similar, ignoring overall BOLD. If you care that one voxel's timecourse has higher BOLD than another (here, like 2 or 3 being higher than 1), you don't want to use Pearson correlation.
tbl <- array(NA, c(5,5));
tbl[1,1] <- cor(data1, data1); # method="pearson" is default
tbl[2,1] <- cor(data1, data2);
tbl[3,1] <- cor(data1, data3);
.... the other table cells ....
tbl[5,5] <- cor(data5, data5);
plot(hclust(as.dist(1-tbl)), xlab="", ylab="", sub="", main="1 - Pearson correlation");
 The coefficient of shape difference metric (page 99 in Romesburg) mixes a bit of the properties of
The coefficient of shape difference metric (page 99 in Romesburg) mixes a bit of the properties of Euclidean distance and Pearson correlation: it ignores additive translations, but is sensitive to proportional translations.
As seen here, like correlation, the coefficient of shape difference considers lines 1 and 2 identical (maximally similar), but unlike correlation, line 3 is not considered identical to line 1. Like Euclidean distance, the coefficient of shape difference considers lines 3 and 4 farther apart than any other pair of lines (correlation listed 1, 2, and 3 as all equally far from line 4).
I didn't find the coefficient in a built-in R function, but its equation (8.3 in Romesburg) is very simple to implement, as in the code below.
I've tried using the coefficient of shape difference in a few analyses, as its property of being sensitive to proportional translations more closely matches my intuitive understanding of "similar" timecourses. I haven't used it in any published analyses yet, as Pearson correlation has done better. But it certainly seems worth considering.
# coefficient of shape difference, page 99 of Romesburg
get.dist <- function(dataA, dataB) {
if (length(dataA) != length(dataB)) { stop("length(dataA) != length(dataB)"); }
n <- length(dataA); # number of dimensions
d <- sqrt((n/(n-1))*(sum((dataA-dataB)^2)/n - ((1/(n^2))*(sum(dataA) - sum(dataB))^2)));
return(d);
}
tbl <- array(NA, c(5,5)); # tbl <- array(NA, c(4,4)); #
tbl[1,1] <- get.dist(data1, data1);
.... the other table cells ....
tbl[5,5] <- get.dist(data5, data5);
plot(hclust(as.dist(tbl)), xlab="", ylab="", sub="", main="coeff of shape diff");
These three ways of measuring the similarity (distance) between timecourses are certainly not the only metrics, but I hope it's clear from just these three that the metric matters; they're not interchangeable.
No comments:
Post a Comment