In a previous post I explained how I thought the pyMVPA normal_feature_dataset function works, drawing from the description in the documentation. But Ben Acland dug through the function and was able to clarify it for me; my previous R code and description isn't right. So here is what mvpa2.misc.data_generators.normal_feature_dataset really seems to be doing (followed by my R version).
normal_feature_dataset description
We first specify snr, which gives the amount of signal in the simulated data (larger number corresponds to more signal) and nonbogus_features, which lists the indices of the voxels which will be given signal.We start making the dataset by generating a number from a standard normal distribution for every cell (all examples, not just ones of a single class). We then divide all values by the square root of the snr. Next, we add signal to the specified nonbogus voxels in each class by adding 1 to the existing voxel values. Finally, each value is divided by the largest absolute value of the for "normalization."
my R version
Here is my R implementation of the pyMVPA normal_feature_dataset function, using the previous code for easy comparison. The code here assumes we have 2 classes, 4 runs, and 10 examples, for 80 rows in our final dataset.num.nonbogus <- c(2,2); # number of voxels to be given signal in each class
temp.vox <- rnorm(40*2, mean=0, sd=1);
temp.vox <- temp.vox / sqrt(pymvpa.snr);
Which voxels get the +1 is specified a bit differently here than in the pyMVPA code; I added it to the first num.nonbogus[1] voxels in class A and the next num.nonbogus[2] in class B. If num.nonbogus[1] + num.nonbogus[2] = (the total number of voxels) then all voxels will be informative, if smaller, some will be "bogus" in the final simulated dataset.
i is the voxel index (which voxel we're generating data for in this iteration). The rows are arranged so that the first 40 rows are class A and the last 40 rows class B.
if (i <= num.nonbogus[1]) {
temp.vox[1:40] <- temp.vox[1:40] + 1; # add to class A
}
if (i > num.nonbogus[1]) & (i <= (num.nonbogus[1] + num.nonbogus[2]))) {
temp.vox[41:80] <- temp.vox[41:80] + 1; # add to class B
}
tbl[,i] <- temp.vox / max(abs(temp.vox));
null distributions
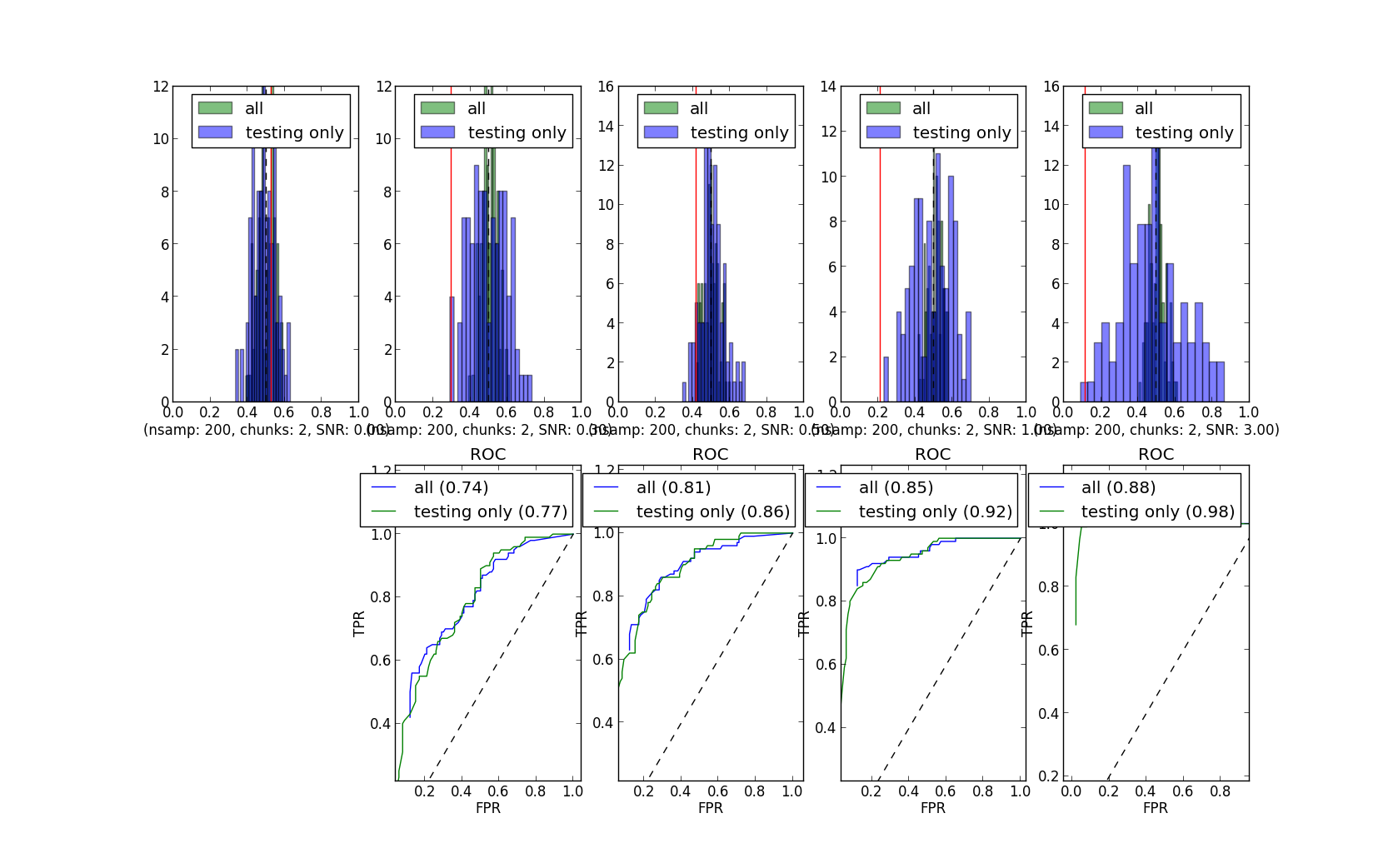
These null distributions are much more "normal" appearing than the ones with my first "pymvpa" way of simulating data, but still become wider at higher snr (particularly when permuting the training data only).

So, this is the third set of null distributions (compare with these and these), in which only the way of simulating the data was varied. How we simulate the data really matters.














{kind=link}